We might be interested in learning whether there is a pattern of movement of a random variable when another random variable moves up or down. An important pattern we can measure is the linear relationship. The main two measures of linear relationship between 2 random variables are:
Covariance and
Correlation
Let’s start with an example. Imagine we want to see whether there is a relationship between the S&P500 and Microsoft stock.
The S&P500 is an index that represents the 500 biggest US companies, which is a good representation of the US financial market. We will use monthly data for the last 3-4 years.
Let’s download the price data and do the corresponding return calculation. Instead of pandas, we will use yfinance to download online data from Yahoo Finance.
import numpy as npimport pandas as pdimport yfinance as yfimport matplotlibimport matplotlib.pyplot as plt# We download price data for Microsoft and the S&P500 index:prices=yf.download(tickers="MSFT ^GSPC", start="2019-01-01",interval="1mo", auto_adjust=True)# We select Adjusted closing prices and drop any row with NA values:adjprices = prices['Close'].dropna()
[ 0% ]
[*********************100%***********************] 2 of 2 completed
GSPC stands for Global Standard & Poors Composite, which is the S&P500 index.
Now we will do some informative plots to start learning about the possible relationship between GSPC and MSFT.
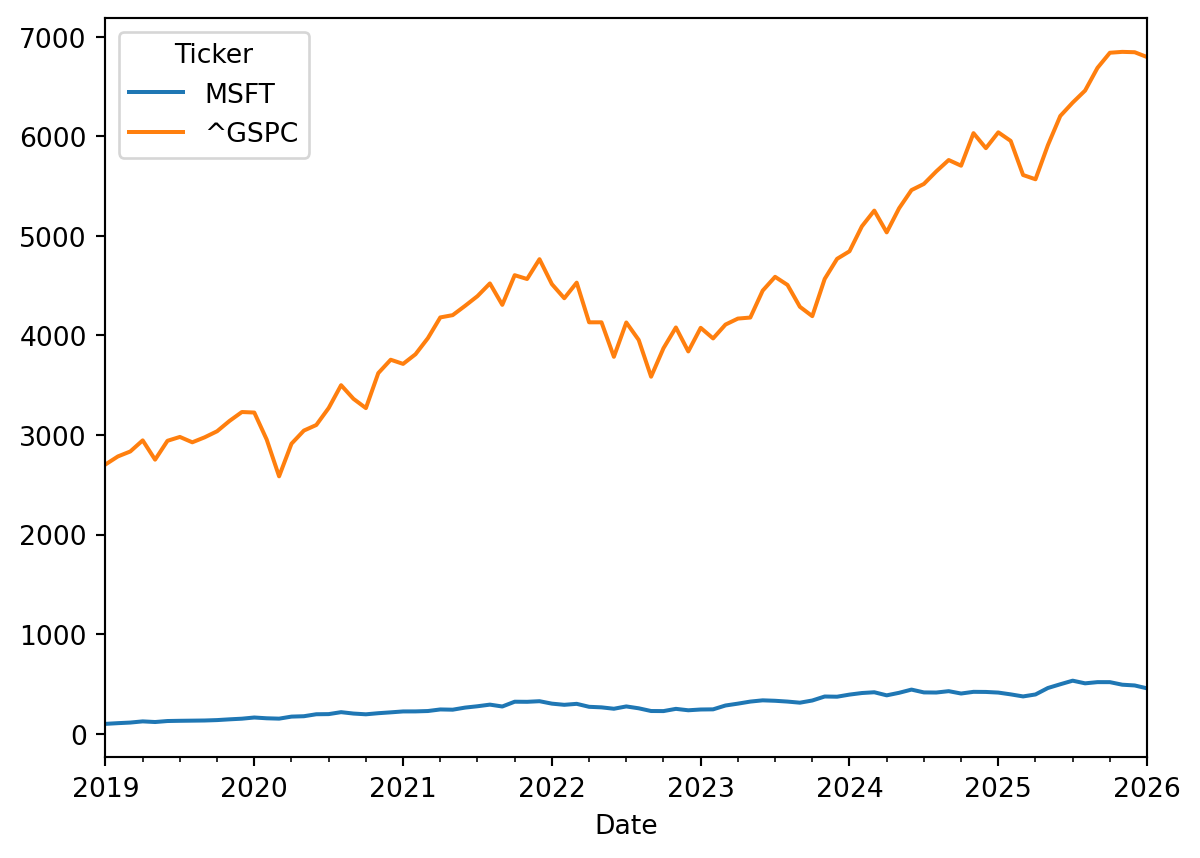
Unfortunately, the range of stock prices and market indexes can vary a lot, so this makes difficult to compare price movements in one plot. For example, if we plot the MSFT prices and the S&P500:
adjprices.plot(y=['MSFT','^GSPC'])plt.show()
It looks like the GSPC has had a better performance, but this is misleading since both investment have different range of prices.
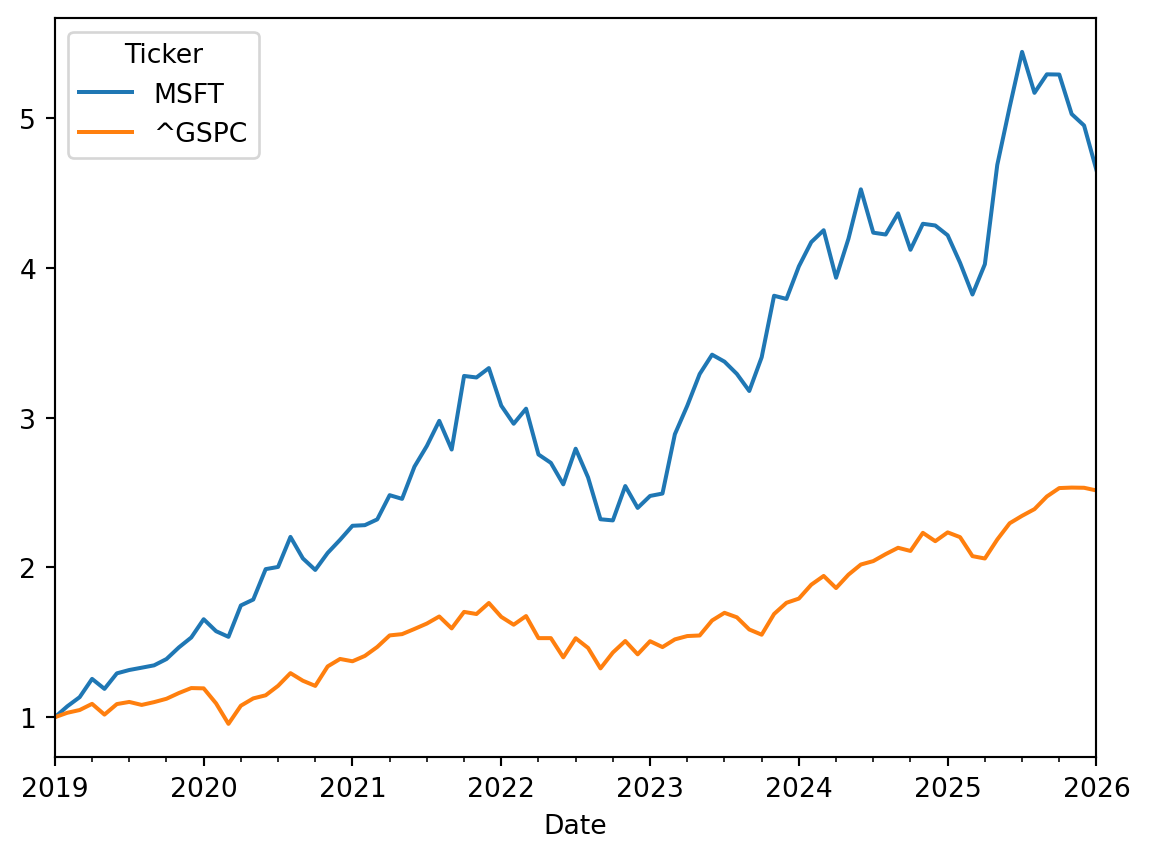
When comparing the performance of 2 or more stock prices and/or indexes, it is a good idea to generate an index for each series, so that we can emulate how much $1.00 invested in each stock/index would have moved over time. We can divide the stock price of any month by the stock price of the first month to get a growth factor:
# I create a dataset to calculate indexes for each variable, where the index value will be a growth factor = its value divided by its first valueindexprices = adjprices / adjprices.iloc[0]
This growth factor is like an index of the original variable. Now we can plot these 2 new indexes over time and see which investment was better:
indexprices.plot(y=['MSFT','^GSPC'])plt.show()
Now we have a much better picture of which instrument has had better performance over time. The line of each instrument represents how much $1.00 invested the instrument would have been changing over time.
Now we calculate continuously compounded monthly returns. In Pandas most of the data management functions works row-wise. In other words, operations are performed to all columns, and row by row:
# I create a new data frame to calculate the log returnsr = np.log(adjprices).diff(1)# The diff function calculates the difference between the log price of t and the log price of t-1# Dropping rows with NA values (the first month has NA's)r = r.dropna()# Renameing the column names to avoid special characters like ^GSPC:r.columns = ['MSFT','GSPC']
Now the r dataframe will have 2 columns for both cc historical returns:
r.head()
MSFT
GSPC
Date
2019-02-01
0.070250
0.029296
2019-03-01
0.055671
0.017766
2019-04-01
0.101963
0.038560
2019-05-01
-0.054442
-0.068041
2019-06-01
0.083539
0.066658
To learn about the possible relationship between the GSPC and MSFT we can look at their prices and also we can look at their returns.
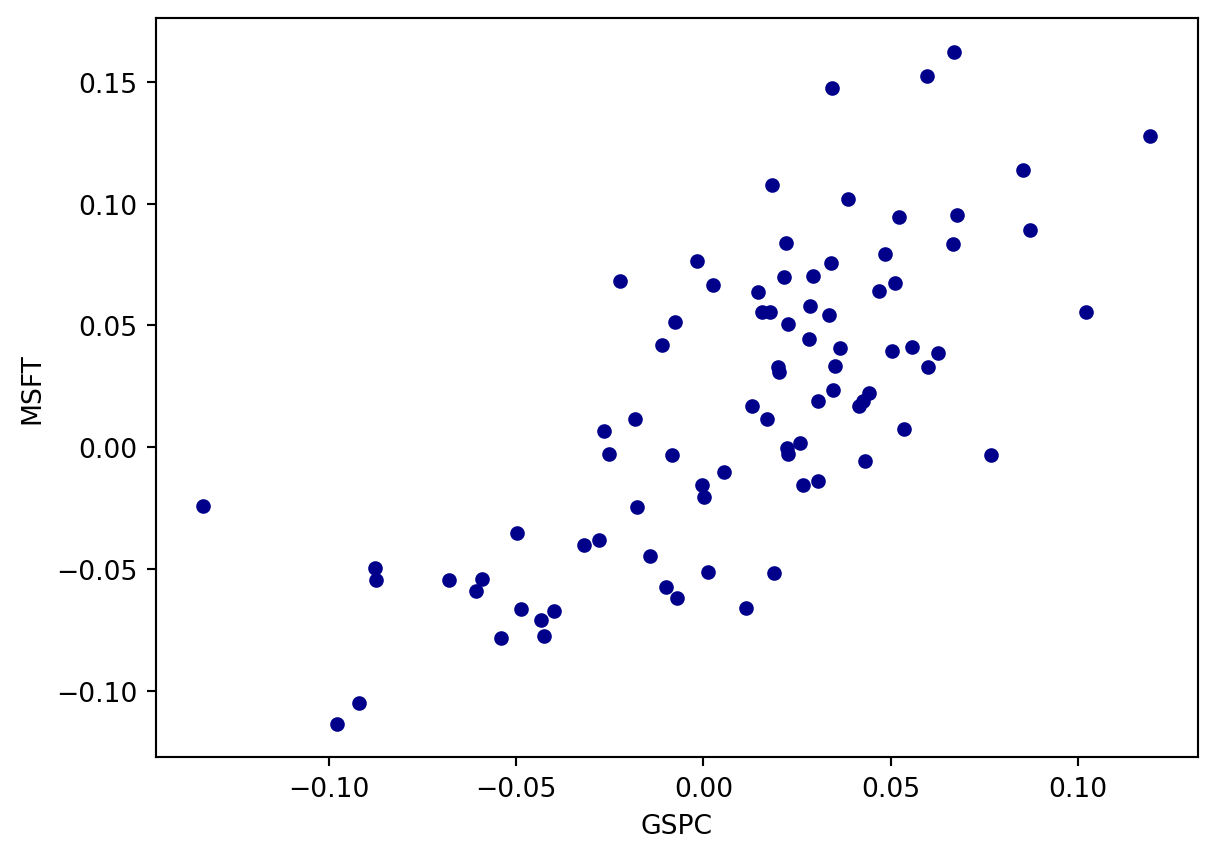
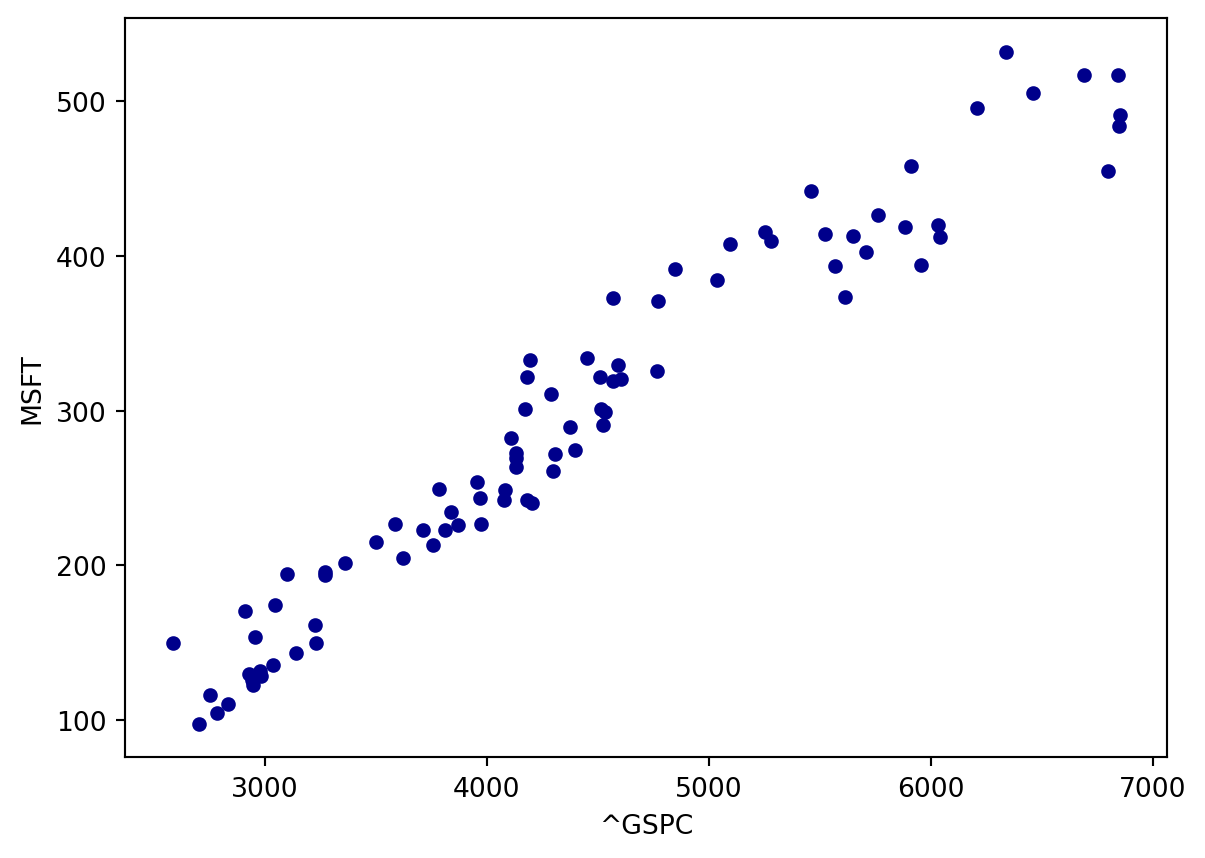
We start with a scatter plot to see whether there is a linear relationship between the MSFT returns and the GSPC returns:
Which plot conveys a stronger linear relationship?
The scatter plot using the prices conveys an apparent stronger linear relationship compared to the scatter plot using returns.
Stock returns are variables that usually does NOT grow over time; they look like a plot of heart bits:
plt.clf()r.plot(y=['MSFT','GSPC'])plt.show()
<Figure size 672x480 with 0 Axes>
Stock returns behave like a stationary variable since they do not have a growing or declining trend over time. A stationary variable is a variable that has a similar average and standard deviation in any time period.
Stock prices (and indexes) are variables that usually grow over time (sooner or later). These variables are called non-stationary variables. A non-stationary variable usually changes its mean depending on the time period.
In statistics, we have to be very careful when looking at linear relationships when using non-stationary variables, like stock prices. It is very likely that we end up with spurious measures of linear relationships when we use non-stationary variables. To learn more about the risk of estimating spurious relationships, we will cover this issue in the topic of time-series regression models (covered in a more advanced module).
Then, in this case it is better to look at linear relationship between stock returns (not prices).
8.1 Covariance
The Covariance between 2 random variables, X and Y, is a measure of linear relationship.
The Covariance is the average of product deviations between X and Y from their corresponding means.
For a sample of N and 2 random variables X and Y, we can calculate the population covariance as:
Why dividing by N-1 instead of N? In Statistics, we assume that we work with samples and never have access to the population, so when calculating a sample measure, we always miss data. The sample formula will calculate a more conservative value than the population formula. That is the reason why we use N-1 as degree of freedom instead of N.
Sample covariance will be always a little bit greater than population covariance, but they will be similar. When N is large (N>30), population and sample covariance values will be almost the same. The sample covariance formula is the default formula for all statistical software.
If Cov(X,Y)>0, we can say that, on average, there is a positive linear relationship between X and Y. If Cov(X,Y)<0, we can say that there is a negative relationship between X and Y.
A positive linear relationship between X and Y means that if X increases, it is likely that Y will also increase; and if X decreases, it is likely that Y will also decrease.
A negative linear relationship value between X and Y means that if X increases, it is likely that Y will decrease; and if X decreases, it is likely that Y will increase.
If we can test that Cov(X,Y) is positive and significant, we need to do a hypothesis test. If the pvalue<0.05 and the Cov(X,Y) is positive, then we can say that we have a 95% confidence that there is a linear relationship.
There is no constraint in the possible values of Cov(X,Y) that we can get:
-\infty<Cov(X,Y)<\infty
We can interpret the sign of covariance, but we CANNOT interpret its magnitude. Fortunately, the correlation is a very practical measure of linear relationship since we can interpret its sign and magnitude since the possible values of correlation goes from -1 to 1 and represent percentage of linear relationship.
Actually, the correlation between X and Y is a standardized measure of the covariance.
8.2 Correlation
Correlation is a very practical measure of linear relationship between 2 random variables. It is actually a scaled version of the Covariance:
Corr(X,Y)=\frac{Cov(X,Y)}{SD(X)SD(Y)}
If we divide Cov(X,Y) by the product of the standard deviations of X and Y, we get the correlation, which can have values only between -1 and +1.
-1<=Corr(X,Y)<=1
If Corr(X,Y) = +1, that means that X moves exactly in the same way than Y, so Y is proportional (in the same direction) than X; actually Y should be equal to X multiplied by number.
If Corr(X,Y) = -1 means that Y moves exactly proportional to X, but in the opposite direction.
If Corr(X,Y) = 0 means that the movements of Y are not related to the movements of X. In other words, that X and Y move independent of each other; in this case, there is no clear linear pattern of how Y moves when X moves.
If 0<Corr(X,Y)<1 means that there is a positive linear relationship between X and Y. The strength of this relationship is given by the magnitude of the correlation. For example, if Corr(X,Y) = 0.50, that means that if X increases, there is a probability of 50% that Y will also increase.
If -1<Corr(X,Y)<0 means that there is a negative linear relationship between X and Y. The strength of this relationship is given by the magnitude of the correlation. For example, if Corr(X,Y) = - 0.50, that means that if X increases, there is a probability of 50% that Y will decrease (and vice versa).
If we want to test that Corr(X,Y) is positive and significant, we need to do a hypothesis test. The formula for the standard error (standard deviation of the correlation) is:
SD(corr)=\sqrt{\frac{(1-corr^{2})}{(N-2)}}
Then, the t-Statistic for this hypothesis test will be:
t=\frac{corr}{\sqrt{\frac{(1-corr^{2})}{(N-2)}}}
If Corr(X,Y)>0 and t>2 (its pvalue will be <0.05), then we can say that we have about 95% confidence that there is a positive linear relationship; in other words, that the correlation is positive and statistically significant (significantly greater than zero).
8.3 Calculating covariance and correlation
We can program the covariance of 2 variables according to the formula:
The cov function calculates the variance-covariance matrix using both returns. We can find the covariance in the non-diagonal elements, which will be the same values since the covariance matrix is symmetric.
The diagonal values have the variances of each return since the covariance of one variable with itself is actually its variance (Cov(X,X) = Var(X) ) .
Then, to extract the covariance between MSFT and GSPC returns we can extract the element in the row 1 and column 2 of the matrix:
cov = covm[0,1]print(f"Covariance of MSFT with GSPC returns = {cov}")# In Python the first row of an array or a data frame has the position number zero.
Covariance of MSFT with GSPC returns = 0.0021417325447086
This value is exactly the same we calculated manually.
We can use the corrcoef function of numpy to calculate the correlation matrix:
The correlation matrix will have +1 in its diagonal since the correlation of one variable with itself is +1. The non-diagonal value will be the actual correlation between the corresponding 2 variables (the one in the row, and the one in the column).
We could also manually calculate correlation using the previous covariance:
corr2 = cov / (r['MSFT'].std() * r['GSPC'].std())corr2print(f"The correlation between MSFT and GSPC returns is = {corr2}")
The correlation between MSFT and GSPC returns is = 0.7086865098949171
We can use the scipy pearsonr function to calculate correlation and also the 2-tailed pvalue to see whether the correlation is statistically different than zero:
from scipy.stats import pearsonrcorr2 = pearsonr(r['MSFT'],r['GSPC'])print(corr2)
The pvalue is almost zero (1.5 * 10^{-13}) . MSFT and GSPC returns have a positive and very significant correlation (at the 99.9999…% confidence level).