import numpy as np
from scipy import stats
import matplotlib.pyplot as plt6 Chapter 6 - The Central Limit Theorem
6.1 What is the Central Limit Theorem?
The Central Limit Theorem (CLT) is one of the most important discoveries in the history of mathematics and statistics. Actually, thanks to this discovery, the field of Statistics was further developed at the the end of the 19th and beginning of the 20th century.
The central limit theorem says that for any random variable with ANY probability distribution, when you take groups (of at least 30 elements from the original distribution), take the mean of each group, then the probability distribution of these means will have the following characteristics:
The distribution of the sample means will be close to normal distribution when you take many groups (the size of the groups should be each equal or bigger than 25). Actually, this happens not only with the sample mean , but also with other linear combinations such as the sum or weighted average of the variable.
The standard deviation of the sample means will be much less than the standard deviation of the individuals. Being more specifically, the standard deviation of the sample mean will shrink with a factor of* 1/\sqrt{N}
Then, the central limit theorem says that, no matter the original probability distribution of any random variable, if we take groups of this variable, a) the means of these groups will have a probability distribution close to the normal distribution, and b) the standard deviation of the mean will shrink according to the number of elements of each group.
Two interesting questions about the CLT are:
Why the standard deviation of means shrinks so much with a factor of 1/\sqrt{N}?
Why the means of groups composed of individuals with any probability distribution behave like a normal distributed variable?
Let’s try to respond these two questions.
6.2 Why the variability of means of X shrinks?
Intuitively, when you take groups and then take the mean of each group, then extreme values (very low or negative values and very high positive values) that you could have in each group will cancel each other out when you take the average of the group. Then, it is expected that the variance of the mean of the group will be much less than variance of the variable. But how much less?
Now let’s use simple math and probability theory to see how much the variance of the means decrease with respect to the variance of the individuals:
Let’s define a random variable X as a the weight of students X1, X2, … XN. The mean will be:
\bar{X}=\frac{1}{N}\left(X_{1}+X_{2}+...+X_{N}\right)
We can estimate the variance of this mean as follows:
VAR\left(\bar{X}\right)=VAR\left(\frac{1}{N}\left(X_{1}+X_{2}+...+X_{N}\right)\right)
Applying basic probability rules I can express the variance as:
VAR\left(\bar{X}\right)=\left(\frac{1}{N}\right)^{2}VAR\left(X_{1}+X_{2}+...+X_{N}\right)
VAR\left(\bar{X}\right)=\left(\frac{1}{N}\right)^{2}\left[VAR\left(X_{1}\right)+VAR\left(X_{2}\right)+...+VAR\left(X_{N}\right)\right]
Since the variance of X_1 is the same as the variance of X_2 and it is also the same for any X_N, then:
VAR\left(\bar{X}\right)=\left(\frac{1}{N}\right)^{2}N\left[VAR\left(X\right)\right]
Then we can express the variance of the mean as:
VAR\left(\bar{X}\right)=\left(\frac{1}{N}\right)\left[VAR\left(X\right)\right]
We can say that the expected variance of the sample mean is equal to the variance of the individuals divided by N, that is the sample size.
Finally we can get the sample standard deviation by taking the square root of the variance:
SD(\bar{X})=\sqrt{\frac{1}{N}}\left[SD(X)\right]
SD(\bar{X})=\frac{SD(X)}{\sqrt{N}}
Then the expected standard deviation of the sample mean of a random variable is equal to the individual standard deviation of the variable divided by the squared root of N.
6.3 Why the distribution of any group of sample means behave normal?
To respond this question I will do a fun exercise with random generated numbers. With this excercise I will respond to both questions related to the CLT: why the sample mean variance shrinks and why the behave like a normal distributed variable.
Creating random numbers that follow specific probability distributions is called Monte Carlos simulation.
Then I will do Monte Carlo simulations to illustrate the CLT.
Before we do this exercise, I will review the uniform probability distribution.
Let’s start
6.3.1 The Uniform Probability Distribution
The traditional lottery is an example of the discrete uniform probability distribution. For example, if the lottery has 100,000 numbers, from 1 to 100,000, then each number has the same probability of being the winner. This probability is 1 / 100,000 =0.00001.
We can think in the continuous version of a uniform probability distribution where any real number can appear between the minimum and a maximum possible values. If we define a as the minimum possible value and b as the maximum possible value, then the probability density function (PDF) for a uniform variable is the following:
f(x)=\left\{ \begin{array}{c} \frac{1}{(b-a)};a<=x<=b\\ 0;otherwise \end{array}\right\}
Then the function is equal to zero for values outside the range between a and b.
(1 / (b-a)) is the probability for any value between a and b to show up. Then, any value between a and b has the same probability to show up.
The area under the function (the rectangle created with this function) is (b-a)(1 / (b-a)), which is 1 (100%) since it is a PDF.
For example, if a=0 and b=40, then for the range from 0 to 40 the function is f(x)=1/40. If we imagine the plot of this function, this will be a rectangle with base = 40 and height = 1/40, so the area will be equal to 1.
The expected value of this x random variable is given by:
E(x)=\frac{a+b}{2}
Why this is true?
Let’s apply the expected value to the PDF:
E\left[x\right]=\int_{_{-\infty}}^{+\infty}xf\left(x\right)dx
E\left[x\right]=\int_{_{-\infty}}^{+\infty}x\frac{1}{b-a}dx Since a and b are constants:
E\left[x\right]=\frac{1}{b-a}\int_{_{-\infty}}^{+\infty}xdx Solving for the defined integral and considering the range of the uniform
E\left[x\right]=\frac{1}{b-a}\frac{x^2}{2}\mid^{b}_{a}
E\left[x\right]=\frac{1}{b-a}\frac{b^{2}-a^{2}}{2}=\frac{(b-a)(b+a)}{2(b-a)}=\frac{(b+a)}{2}
This is actually the mid point of the range from a to b.
If a=0 and b=40, then the expected value of x will be:
E[x]= 40/2 = 20
The expected value of a random variable is the theoretical mean of the random variable according to its probability distribution.
The variance of a variable with the uniform distribution is:
Var(x)=\frac{(b-a)^2}{12} Why this is true?
According to the definition of Expected value of a continuous random variable:
E\left[x\right]=\int_{_{-\infty}}^{+\infty}xf\left(x\right)dx
In this case, the Variance is the Expected value of the squared deviations, and we learned from previous chapter that it is also equal to:
E\left[(x-E[x])^2\right]=E[x^2]-\overline{x}^2=E[x^2]-E[x]^2
We now E[x]. We need to estimate E[x^2]. Then:
E[x^2] = \int_{_{-\infty}}^{+\infty}x^2f\left(x\right)dx
Solving the integral:
E[x^2] = \int_{_{a}}^{b}x^2\frac{1}{b-a}= \frac{x^3}{3(b-a)}\mid^b_a
E[x^2] = \frac{1}{3(b-a)}\left(b^3-a^3\right)
Factorizing b^3-a^3:
E[x^2]=\frac{(b-a)(b^2+ab+a^2)}{3(b-a)}=\frac{b^2+ab+a^2}{3}
Now the Variance of X is:
VAR(x)= E[x^2] - E[x]^2
Then:
VAR(x)= \frac{b^2+ab+a^2}{3} - \left(\frac{(b+a)}{2}\right)^2
Simplifying we get:
VAR(x)= \frac{b^2+ab+a^2}{3} - \frac{(b^2+a^2+2ab)}{4}
VAR(x)= \frac{4b^2+4ab+4a^2- 3b^2-3a^2-6ab}{12} VAR(x)= \frac{b^2-2ab+a^2}{12} Finally:
VAR(x) = \frac{\left( b-a\right)^2}{12}
In our example, a=0, b=40, then the expected variance of x will be:
Var(x)=(40-0)^2 / 12 = 133.333
Now we will simulate numbers of a uniform random distributed variable.
6.3.2 Simulating numbers with the UNIFORM probability distribution
I define a uniform random variable X and simulate 10,000 uniform random numbers with values from 0 to 40:
# -----------------------------
# 1) Uniform(0, 40)
# -----------------------------
plt.clf()
# Reproducible RNG
#rng = np.random.default_rng(2025)
uniform = stats.uniform(loc=0, scale=40) # U(0, 40)
#x = uniform.rvs(size=10_000, random_state=rng)
x = uniform.rvs(size=10_000)
# Show a histogram of the 10,000 random uniform numbers:
plt.figure(figsize=(7,4))
plt.hist(x, bins=50, edgecolor="white")
plt.title("Samples from Uniform(0, 40)")
plt.xlabel("x")
plt.ylabel("Count")
plt.tight_layout()
plt.show()<Figure size 672x480 with 0 Axes>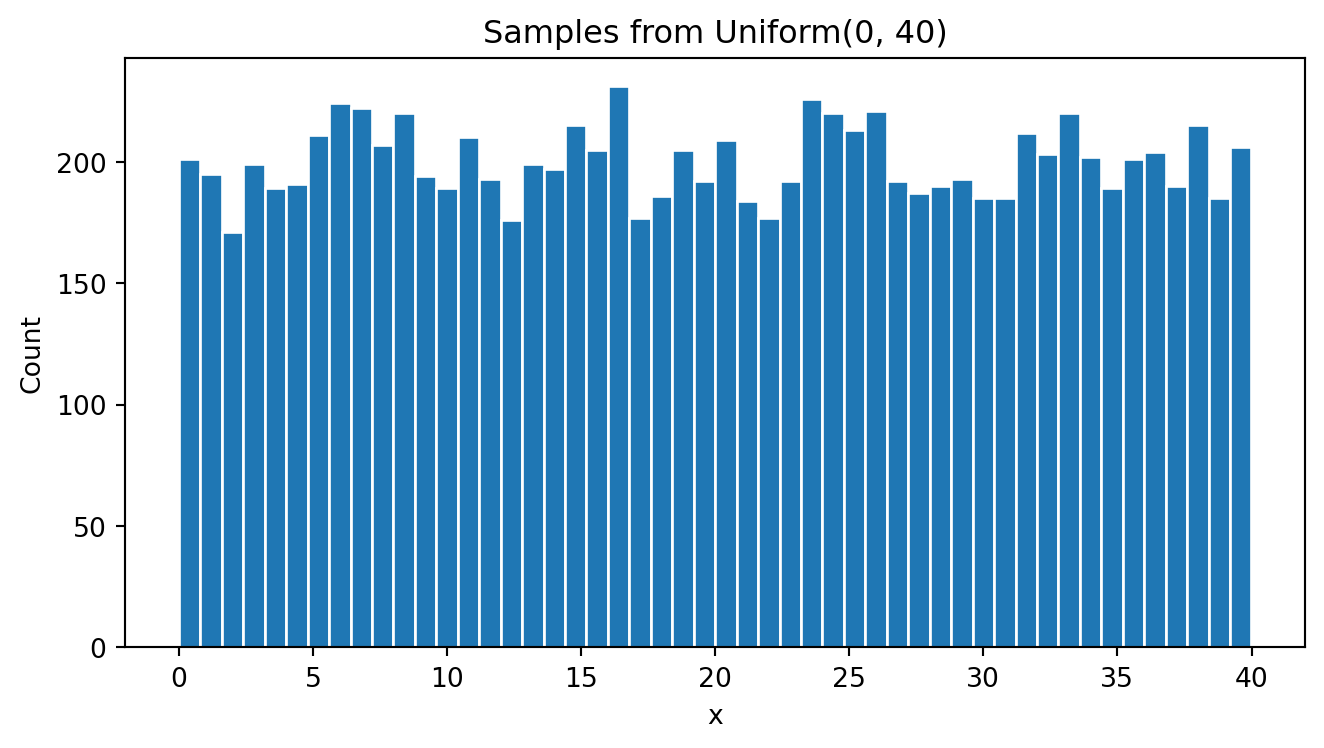
As expected, the histogram looks like a uniform distributed variable where each range of values has similar number of cases.
I can calculate the actual mean and standard deviation:
# Mean of X
print(x.mean())
# SD of X
print(x.std())19.980421431791875
11.635915461431209Now generate 10,000 groups of 25 uniform random variables to end up in a matrix of 10,000 rows and 25 columns:
# Vector of 25 Uniform(0, 40) RVs; simulate 10,000 vectors
xmatrix = uniform.rvs(size=(10_000, 25))
print("xmatrix shape:", xmatrix.shape)xmatrix shape: (10000, 25)Now xmatrix will have 10,000 rows and 25 columns of uniform random numbers between 0 and 40:
xmatrix.shape(10000, 25)Now I get the mean of each row, so we end up with 10,000 sample means:
# Means across each 25-draw row
xmean = xmatrix.mean(axis=1)
print(xmean.shape)
xmean(10000,)array([21.6606312 , 19.05258644, 23.72398296, ..., 20.03497127,
20.52543427, 15.99269535], shape=(10000,))Now I do a histogram of these sample means that come from a UNIFORM distribution.
# Plot means
plt.figure(figsize=(7,4))
plt.hist(xmean, bins=50, edgecolor="white")
plt.title("Row means of 25 Uniform(0,40) draws (10,000 rows)")
plt.xlabel("mean of 25 uniforms")
plt.ylabel("Count")
plt.tight_layout()
plt.show()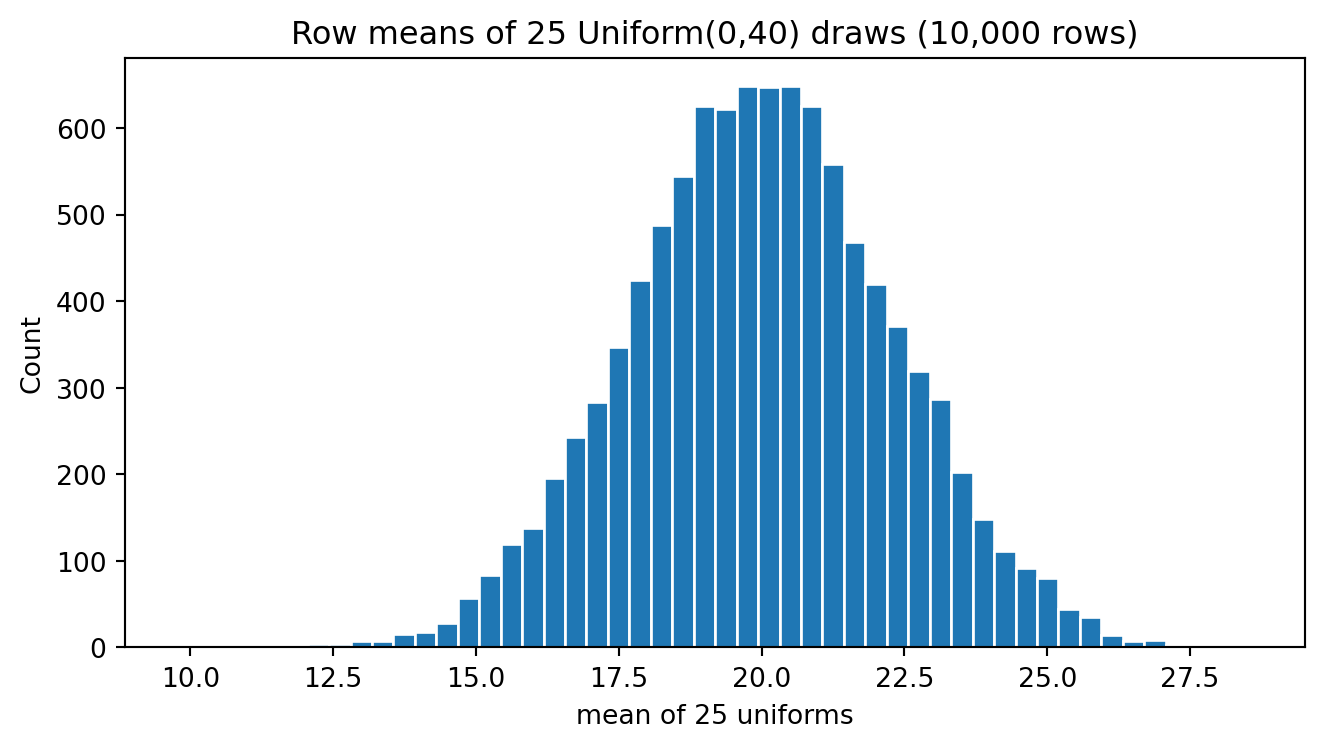
Now I plot both variables in the same plot; the original x uniform variable and the xsample variable (the sample means of x).
# Overlay: means vs single draws
plt.figure(figsize=(7,4))
plt.hist(xmean, bins=50, alpha=0.6, edgecolor="white", label="Means of 25 U(0,40)")
plt.hist(x, bins=50, alpha=0.6, edgecolor="white", label="Single U(0,40) draws")
plt.title("Means vs Single Draws — Uniform(0,40)")
plt.xlabel("Value")
plt.ylabel("Count")
plt.legend()
plt.tight_layout()
plt.show()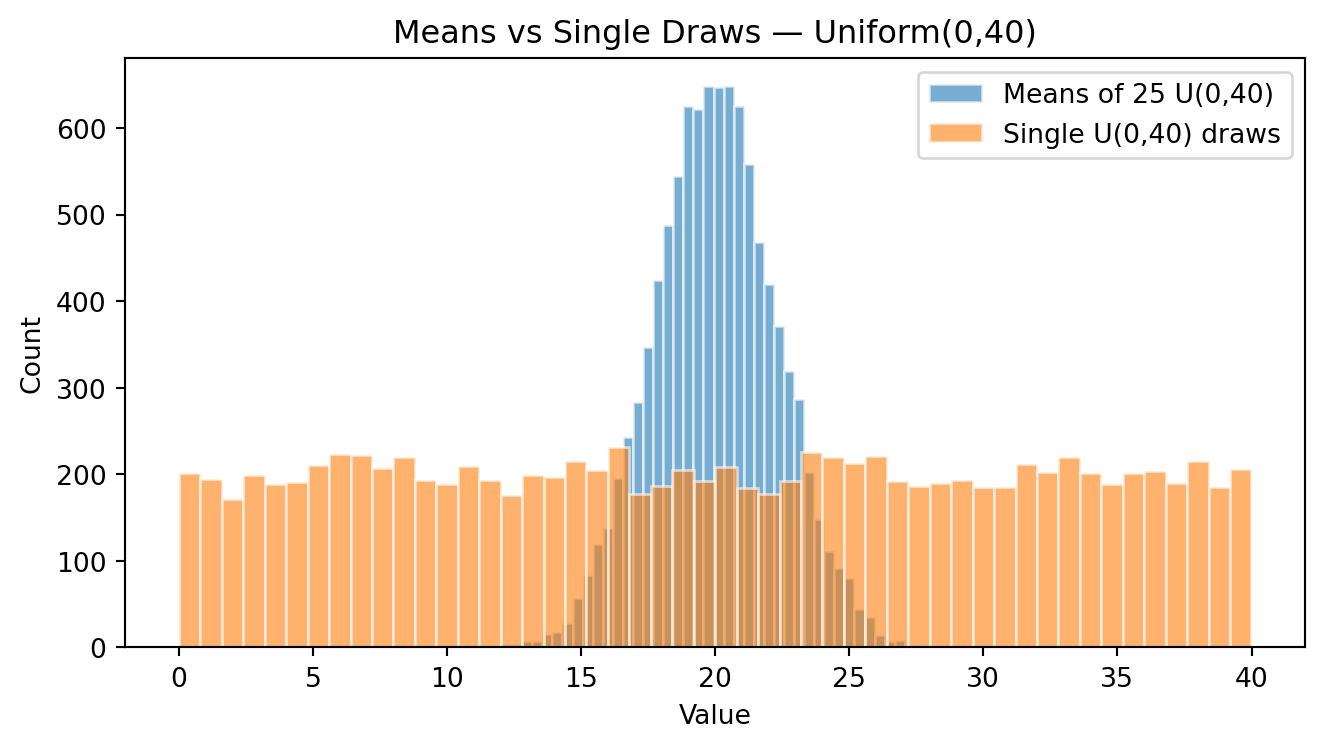
We can see that the mean of both distribution is very similar. However, the variability of the means (xmean) is much less compared to the variability of the individual x.
I can calculate the mean and standard deviation of both, x and the means xmean:
print(x.mean())
print(x.std())
print(xmean.mean())
print(xmean.std())19.980421431791875
11.635915461431209
20.025418705445414
2.2975449312551723Both means are very close to the theoretical mean I used to generate the random numbers. However, the standard deviation of the means is much small than the standard deviation of the individuals.
6.3.3 Simulating numbers with the NORMAL probability distribution
Let’s simulate a normal distributed variable Y with mean = 20 and standard deviation = 10.
# -----------------------------
# 2) Normal(mean=20, sd=10)
# -----------------------------
plt.clf()
normal = stats.norm(loc=20, scale=10)
y = normal.rvs(size=10_000)
# Plotting y:
plt.figure(figsize=(7,4))
plt.hist(y, bins=60, edgecolor="white")
plt.title("Samples from Normal(20, 10)")
plt.xlabel("y")
plt.ylabel("Count")
plt.tight_layout()
plt.show()<Figure size 672x480 with 0 Axes>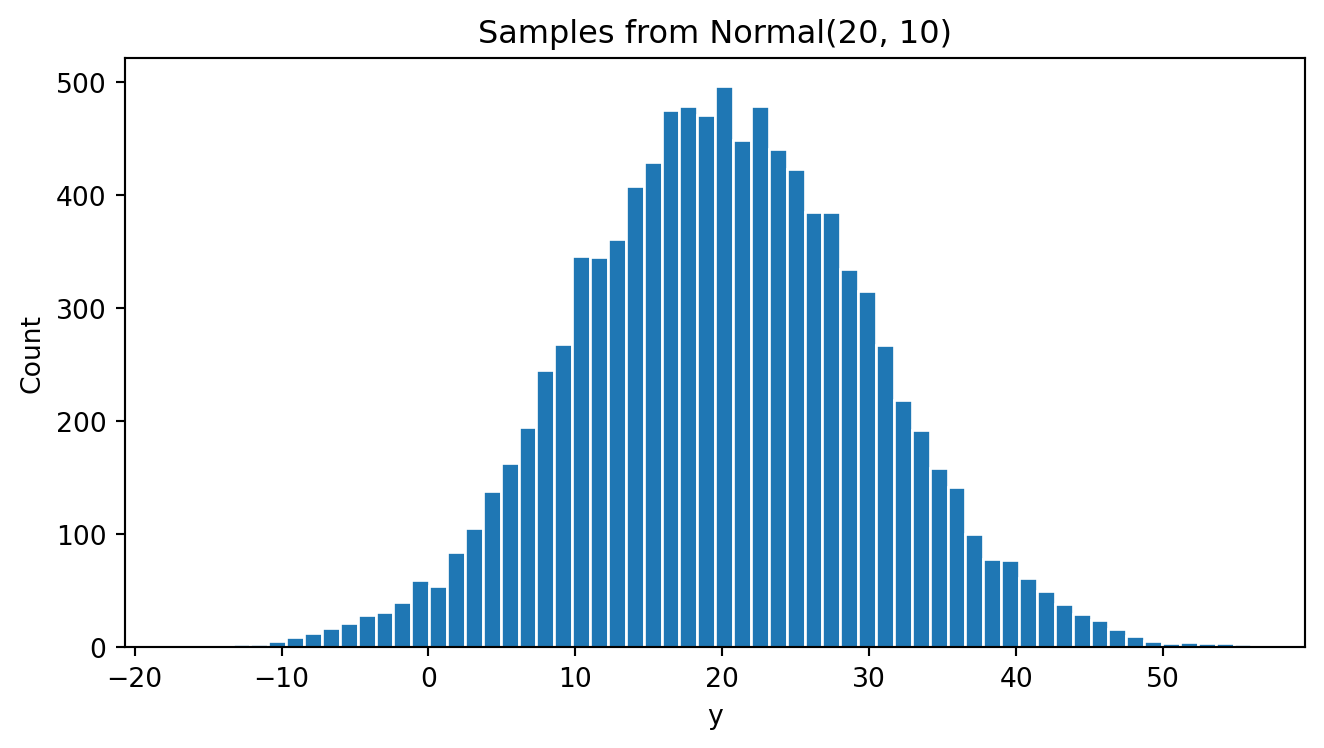
As expected, the y behaves like a normal distributed variable. Most of the y values appear between 0 and +40. The mid point appers close to 20. Then, most of the values of y appear between 2 standard deviations to the left of the mean and 2 standard deviations to the right of the mean.
The mean and standard deviation of the random values (the empirical mean and standard deviation) of y are:
print(y.mean())
print(y.std())19.9353300294757
9.924864069782936As expected, the empirical mean and standard deviation of y are very similar to the theoretical values (mean of 20 and standard deviation of 10)
Now generate 10,000 groups of 25 NORMAL random variables with mean=20 and SD=10. You will end up with a matrix of 10,000 rows and 25 columns:
# Vector of 25 Normals; simulate 10,000 vectors
ymatrix = normal.rvs(size=(10_000, 25))
print("ymatrix shape:", ymatrix.shape)ymatrix shape: (10000, 25)Now ymatrix will have 10,000 rows and 25 columns of NORMAL random numbers with mean=20 and SD=10:
print(ymatrix.shape)(10000, 25)Now we get the mean and standard deviation of each vector (row) to get 10,000 sample means:
# Means across rows
ymean = ymatrix.mean(axis=1)
print(ymean)
print(ymatrix.std(axis=1))[21.2018395 18.89811983 20.54751026 ... 19.90212831 21.47145769
21.18175944]
[ 9.39945419 8.77457471 11.27506781 ... 10.51869364 10.16124033
11.01198968]The mean of the y means is very close to 20, the theoretical mean value. However, the standard deviation of the means of y is much smaller than 10, the theoretical standard deviation of the individuals y. The standard deviation of the sample means is close to 2, which is the individual standard deviation divided by the square root of 25 (the size of each group)!
Now do a histogram of these sample means of Y.
# Plot means
plt.figure(figsize=(7,4))
plt.hist(ymean, bins=60, edgecolor="white")
plt.title("Row means of 25 Normal(20,10) draws (10,000 rows)")
plt.xlabel("mean of 25 normals")
plt.ylabel("Count")
plt.tight_layout()
plt.show()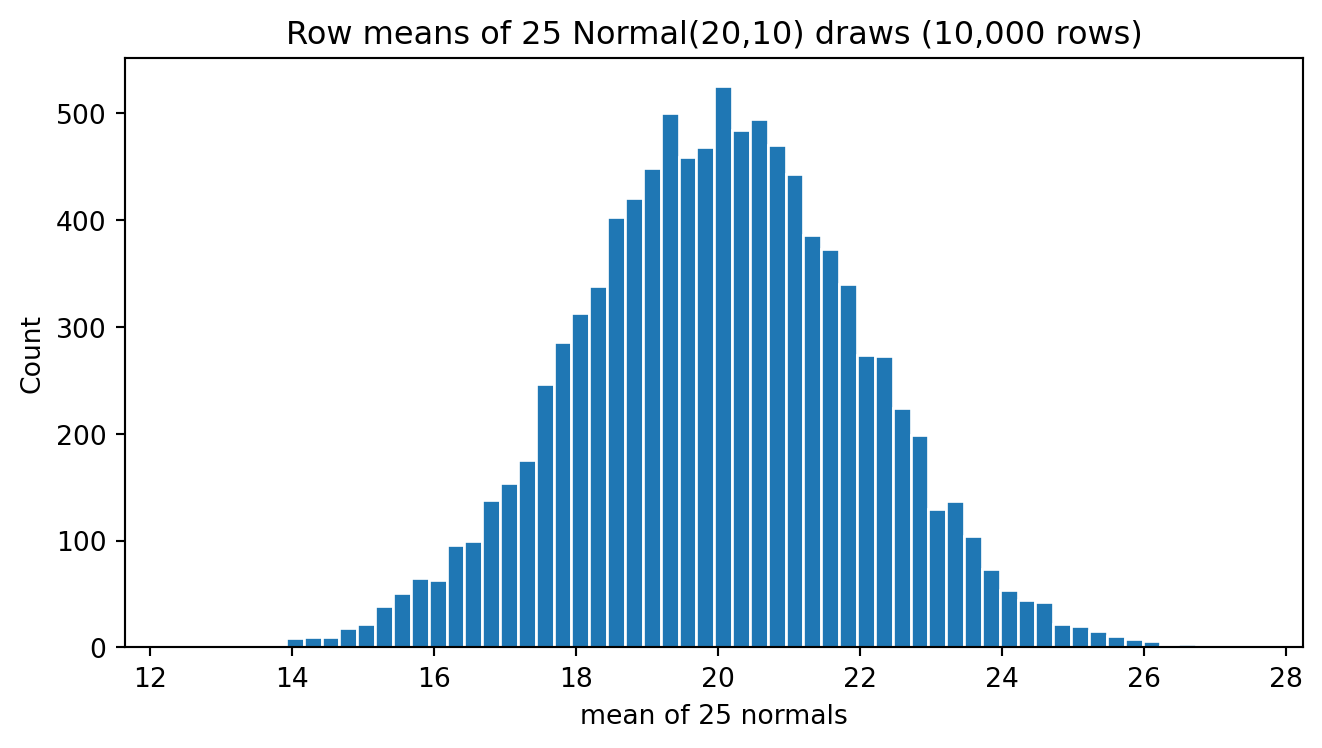
We can see that the variability of these means is much less than the variability of the individuals. Most of the values (about 95%) appear between +6 and +14. If I subtract 2 standard deviations from the mean and add 2 standard deviations from the mean I get this range between 6 and 14.
Now I plot both histograms, the histogram of y and the histogram of ymean:
# Overlay: means vs single draws
plt.figure(figsize=(7,4))
plt.hist(ymean, bins=60, alpha=0.9, edgecolor="white", label="Means of 25 N(20,10)")
plt.hist(y, bins=60, alpha=0.3, edgecolor="white", label="Single N(20,10) draws")
plt.title("Means vs Single Draws — Normal(20,10)")
plt.xlabel("Value")
plt.ylabel("Count")
plt.legend()
plt.tight_layout()
plt.show()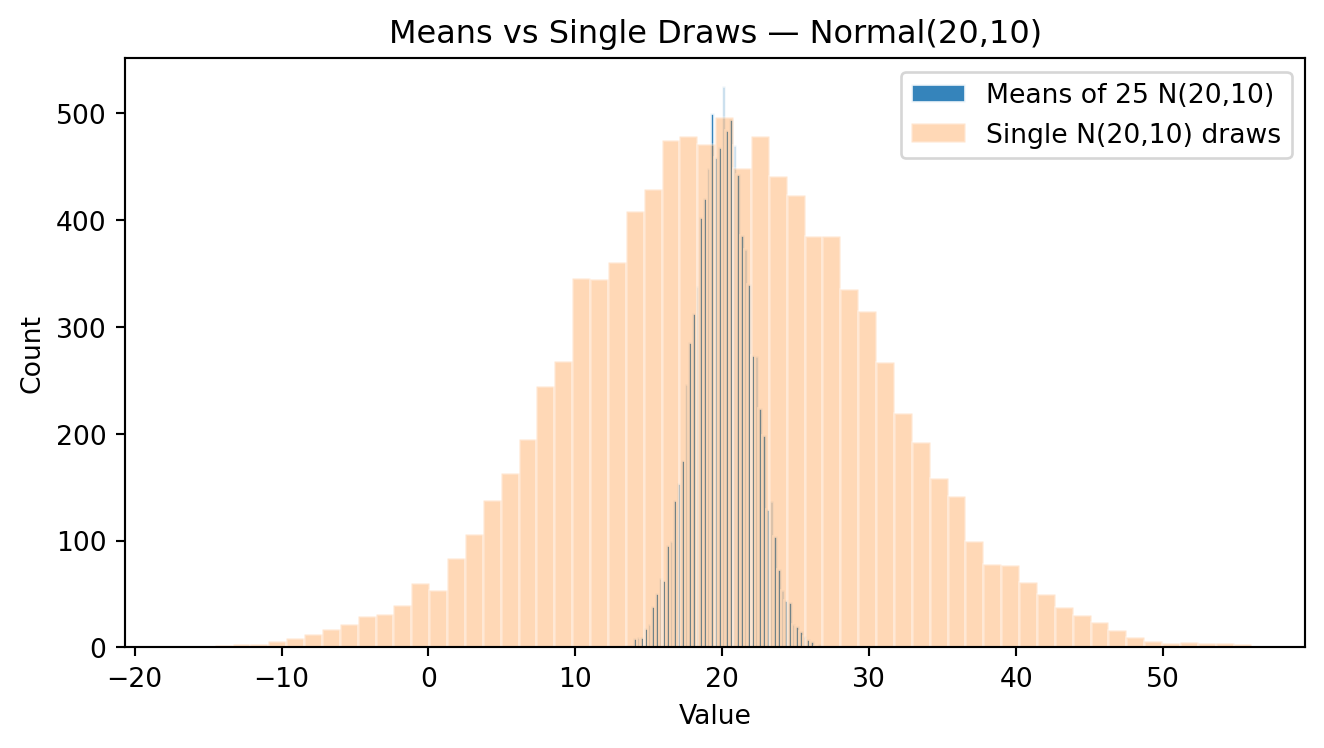
- WHAT DO YOU SEE? COMPARE BOTH HISTOGRAMS. BRIEFLY EXPLAIN WHAT YOU THINK THAT HAPPEND.
6.4 THE CLT DEFINITION
After this experiment, we can write the central limit theorem as follows. For any random variable with any probability distribution, when you take random samples, the sample mean will have the following characteristics:
1) The distribution of the sample means will be close to normal distribution when you take many groups (the size of the groups should be each equal or bigger than 25). Actually, this happens not only with the sample mean , but also with other linear combinations such as the sum or weighted average of the variable.
2) The standard deviation of the sample means will be much less than the standard deviation of the individuals. Being more specifically, the standard deviation of the sample mean will shrink with a factor of 1/\sqrt{N}.
Then, in conclusion, the CLT says that, no matter the original probability distribution of any random variable, if we take groups of this variable, a) the means of these groups will have a probability distribution close to the normal distribution, and b) the standard deviation of the mean will shrink according to the number of elements of each group.