5Chapter 5 - The Histogram and the Normal Distribution
5.1 The Histogram
The histogram was invented to illustrate how the values of a random variable are distributed in its whole range of values. The histogram is a frequency plot. The ranges of values of a variable that are more frequent will have a higher vertical bar compared with the ranges that are less frequent.
With the histogram of a random variable we can appreciate which are the most common values, the least common values, the possible mean and standard deviation of the variable.
In my opinion, the most important foundations/pillars of both, Statistics and the theory of Probability are:
The invention of the Histogram
The discovery of the Central Limit Theorem
Although the idea of a histogram sounds a very simple idea, it took many centuries to be developed, but it has profound impact in the development of Probability theory and Statistics, which both are the pillars of all sciences.
I enjoy learning about the origins of the great ideas of humanity. The idea of the histogram was invented to decipher encrypted messages.
5.1.1 Interesting facts about the History of the Histogram
It is documented that the encryption of messages -cryptography- was commonly used since the beginning of civilizations. Unfortunately, it seems cryptography was invented by ancient Kingdoms mainly for war strategies. According to Herodotus, in the 500s BC, the Greeks used cryptography to win a war against the powerful Persian troops (Singh 2000).
Cryptography refers to the methods of ciphering messages, while cryptanalysis refers to the methods to decipher encrypted messages.
The Arabs in the years 800-900 AD were among the first to decipher encrypted messages thanks to their invention about the idea of the histogram. According to Singh (2000) and Al-Kadit (1992), in 1987 several ancient Arabic manuscripts related to cryptography and cryptanalysis (written between the year 800 AD and 1,500 AD) were discovered in Istanbul, Turkey (they were translated into English until 2002). This is a very fascinating story!
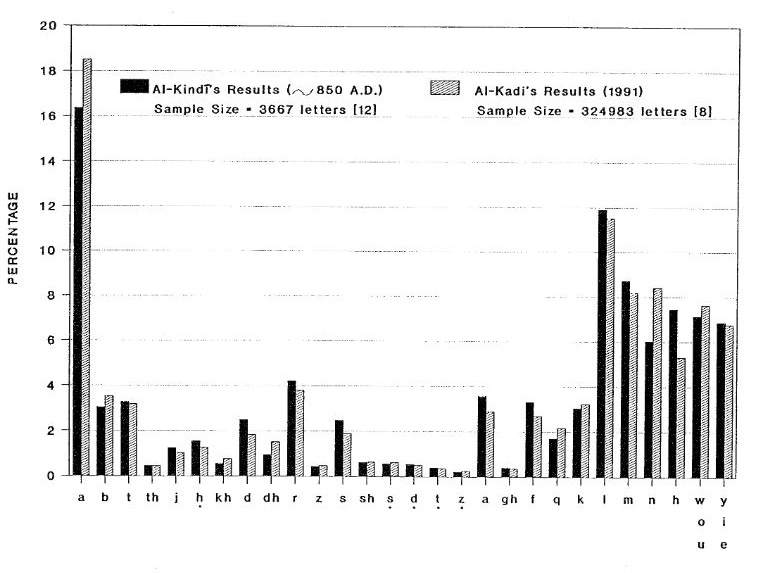
Below is an example of a frequency plot by Arabic philosopher Al-Kindi in the 850 AD compared with a recent frequency plot by Al-Kadi:
The encrypted messages at that time were written with the Caesar shift method. Then, to decipher an encrypted message, the Arabs used to count all characters to create a frequency plot, and then try to match the encrypted characters with the Arab characters. Finally, the replaced the corresponding Arabic matched characters in the original message to decipher it.
Interestingly, the idea of the frequency waited about 1,000 years to be used by French mathematicians to develop the foundations of the Statistics discipline. In the1700s and early 1,800s, the french mathematicians Abraham De Moivre and Pierre-Simon Laplace used this idea to develop the Central Limit Theory (CLT).
I believe the CLT is one of the most important and fascinating mathematical discoveries of all time.
The English scientist Karl Pearson coined the term histogram in 1891 when he was developing statistical methods applied to Biology.
Why the histogram is so important in Statistics? I hope we will find this out during this course!
5.2 Illustrating the Histogram
I get daily data instead of monthly, I change the interval parameter to “1d”:
# !pip install yfinanceimport yfinance as yfimport numpy as npimport pandas as pdBTC=yf.download(tickers="BTC-USD", start="2017-01-01",interval="1d")# I calculate simple and cc return columns:BTC["R"] = (BTC["Close"] / BTC["Close"].shift(1)) -1BTC["r"] = np.log(BTC['Close']).diff(1)# I keep a new object with only returns:BTCR = BTC[['R','r']].copy()
[*********************100%***********************] 1 of 1 completed
Code
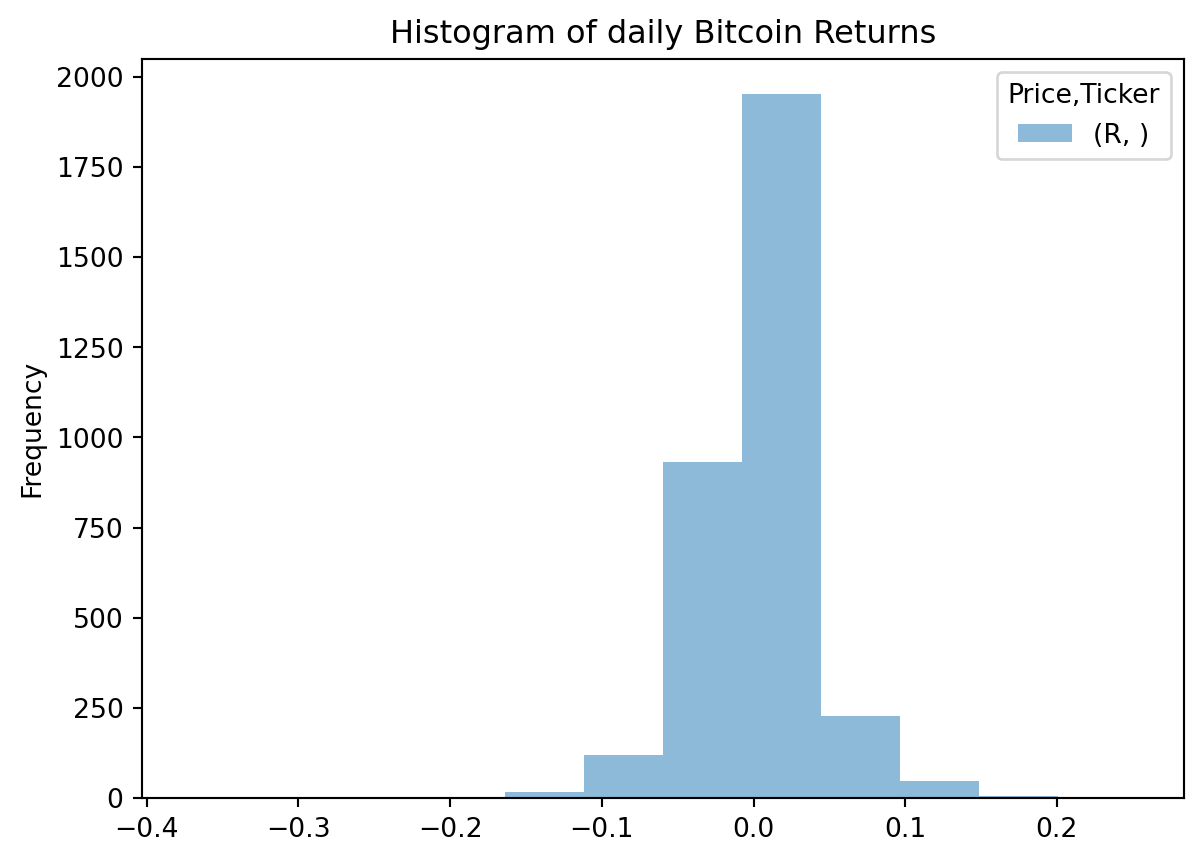
R_bitcoin = pd.DataFrame(BTCR[["R"]])hist=R_bitcoin.plot.hist(bins=12,alpha=0.5,title="Histogram of daily Bitcoin Returns")
We use the histogram to visualize random variables with historical values. For expected values of random variables we can use the concept of probability density function, which is analogous to the concept of the histogram, but applied to the expectation of possible values of a random variable.
5.3 Probability Density Functions (PDF)
5.3.1 Probability Density Function of a Discrete random variable
The Probability Density Function (PDF) of a discrete random variable X is the probability of X to be equal to a specific value x_{i}:
f(x)=P(X=x_{i})
For example, when throwing a dice there are six possible outcomes: 1,2,3,4,5 and 6. All of them with the same probability since these outcomes are independent events. Every outcome has a 1/6 chance of happening. The PDF for a fair six-sided dice can be defined as:
f(x)=P(X=x_{i})=\frac{1}{6}
Where x_i=1,2,3,4,5,6
Now, instead of considering the probability of every independent outcome to take place, you might wonder about the probability of getting any number equal or less than x_{i} when throwing a dice. It seems pretty obvious that the probability would be 50% for x_{i}=3 and 100% for x_{i}=6. In plain words, we can say that getting 1,2 or 3 are 50% of the cases when throwing a dice, and a range from 1 to 6 will cover all the possibilities.
Mathematically we can express the Cumulative Density Function (CDF) as:
f(x)={\sum_{i=1}^{n}}P(X=x_{i})
Following the example of the dice, we can compute the CDF for every possible outcome as follows:
P(X\leq1)=\frac{1}{6}=0.17
P(X\leq2)=\frac{2}{6}=0.33
P(X\leq3)=\frac{3}{6}=0.50
P(X\leq4)=\frac{4}{6}=0.67
P(X\leq5)=\frac{5}{6}=0.83
P(X\leq6)=\frac{1}{6}=1
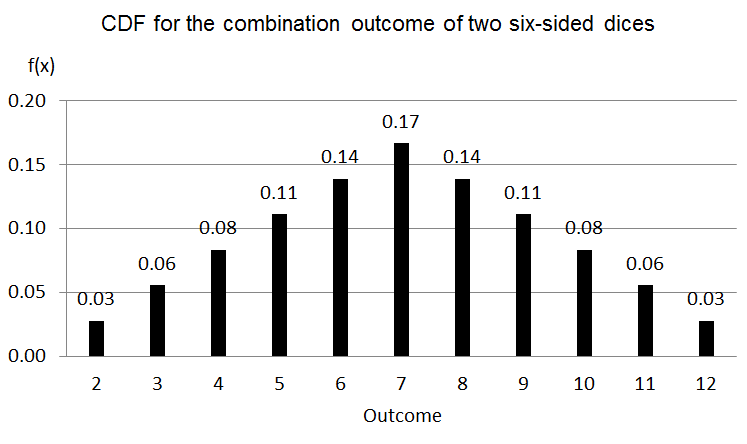
We have covered the PDF and the CDF for a six-sided dice which results are very intuitive if you have played with a dice, but what about if we combine the results from two dices? In any case, knowing about the possibilities of the combination of two dices will be most useful than the results of one single dice since most of the games and casinos around the world use a couple of dices, right? When we consider the sum of two dices (S), the range of possible outcomes goes from 2 to 12, so the PDF is defined as f(S)=P(S=x_{i}), where i=2,3,4..,12. In this case we have a total of 36 possible combinations, where only one combination will give an outcome equal to 2 or 12, there are two different combinations to get a 3 or 11, and so on. The outcome with higher probability to happen is a 7, there are six combinations that will result in a 7, as you can see in the table and graph below:
S
2
3
4
5
6
7
8
9
10
11
12
f(S)
1/36
2/36
3/36
4/36
5/36
6/36
5/36
4/36
3/36
2/36
1/36
We can see this PDF as follows:
The shape of this PDF for the combination outcome of two dices looks like the famous “bell-shaped” of the normal distribution. However there is an elemental difference between this PDF and the normal distribution; the normal distribution is the probabilistic distribution of a continuous random variable, but not a discrete random variable such as the outcome from two dices.
5.3.2 Probability density function (PDF) of a Continuous Random Variable
As seen in previous section, the CDF of a discrete random variable is defined as the sum of the probabilities of the independent outcomes. However, when using a continuous random variable the CDF will be defined as the integration of the function f(x) (f(x) is the PDF).
In this case we will not compute the probability of the variable X to take particular value, as we did with a discrete variable. Instead of doing that, we will calculate the probability of the continuous variable X to be within a specific range limited by a and b. The probability of a continuous variable to take a specific value is zero. The CDF will be 1 or 100% for all possible values that x can take, so:
\sideset{}{_{-\infty}^{\infty}}\intop f(x)\,dx=1
\sideset{}{_{a}^{b}}\intop f(x),dx=P(a\leq x\leq b)
The probability that a continuous random variable X is between a and b, is equal to the area under the PDF on the interval [a,b]. For example, if a PDF is defined as f(x)=3x^{2};0<=x<=1 we can then compute the CDF for the interval between 0.5 and 1 as follows:
As demonstrated, given a PDF=f(x)=3x^{2}, the probability that X is between 0.5 and 1 is equal to 87.5%. In the same way, if you would like to know the probability that X is between 0 and 0.5, all we have to do is to evaluate the CDF for those limits.
If you see, that makes sense since 12.5% is the complement of 87.5%, so that the probability that x lies between 0 and 1 will be 1. This is true since the possible range of x as defined for this PDF is 0<=x<=1, so the probability of x being in any place of this range must be one or 100%. Note that not any arbitrary function is a PDF. A very important condition is that the integral of the function between the possible range of x must be equal to one.
Now we move to the most famous PDF, the Normal Distribution Function.
6 The Normal Distribution Function
In statistics, the most popular continuous PDF is the well-known “bell-shaped” normal distribution, which PDF is defined as:
where \mu is the mean of the distribution and \sigma^{2} is the variance of the distribution. For simplification purposes, the normal distribution can also be denoted as X\sim N(\mu,\sigma^{2}) where X is the continuous random variable, "\sim" means distributed as and N means normal distribution.
So the only two parameters to be defined in order to know the behavior of the continuous random variable X are:
The mean of X and
the the variance of X.
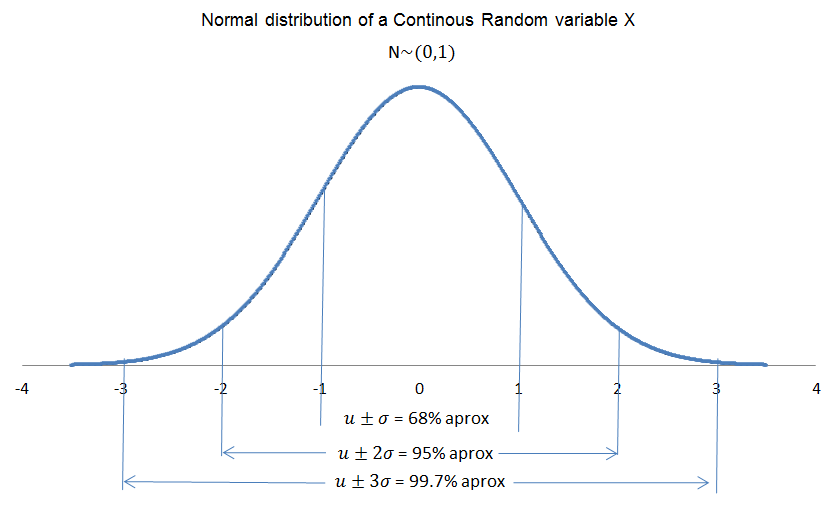
The normal distribution is symmetric around \mu.
Other interesting property of the normal distribution is the probabilities according to different ranges of X:
• For the range (\mu-\sigma)<=x<=(\mu+\sigma), the area under the curve is approximately 68%
• For the range (\mu-2\sigma)<=x<=(\mu+2\sigma), the area under the curve is approximately 95%
• For the range (\mu-3\sigma)<=x<=(\mu+3\sigma), the area under the curve is approximately 99.7%.
If our variable of interest is simple returns (R) and these returns follow a normal distribution r\sim N(\mu,\sigma^{2}), the expected value of the future cc returns will be the mean of the distribution, while the standard deviation can be seen as a measure of risk.
6.1 Interesting facts about the History of the Normal Distribution
The Normal Distribution function is one of the most interesting finding in Statistics. The normal distribution can explain many phenomena in our real world; from financial returns to human behavior, to human characteristics such as height, etc.
Many people believe that Carl Friedrich Gauss was the person who discover it, but it is not quite true. The French mathematician Abraham de Moivre was the first to discover the normal distribution when he found the distribution of the sum of binomial independent random variables.
Very interesting Story… it’s pending … check later for an update!
6.2 Simulating the normal distribution
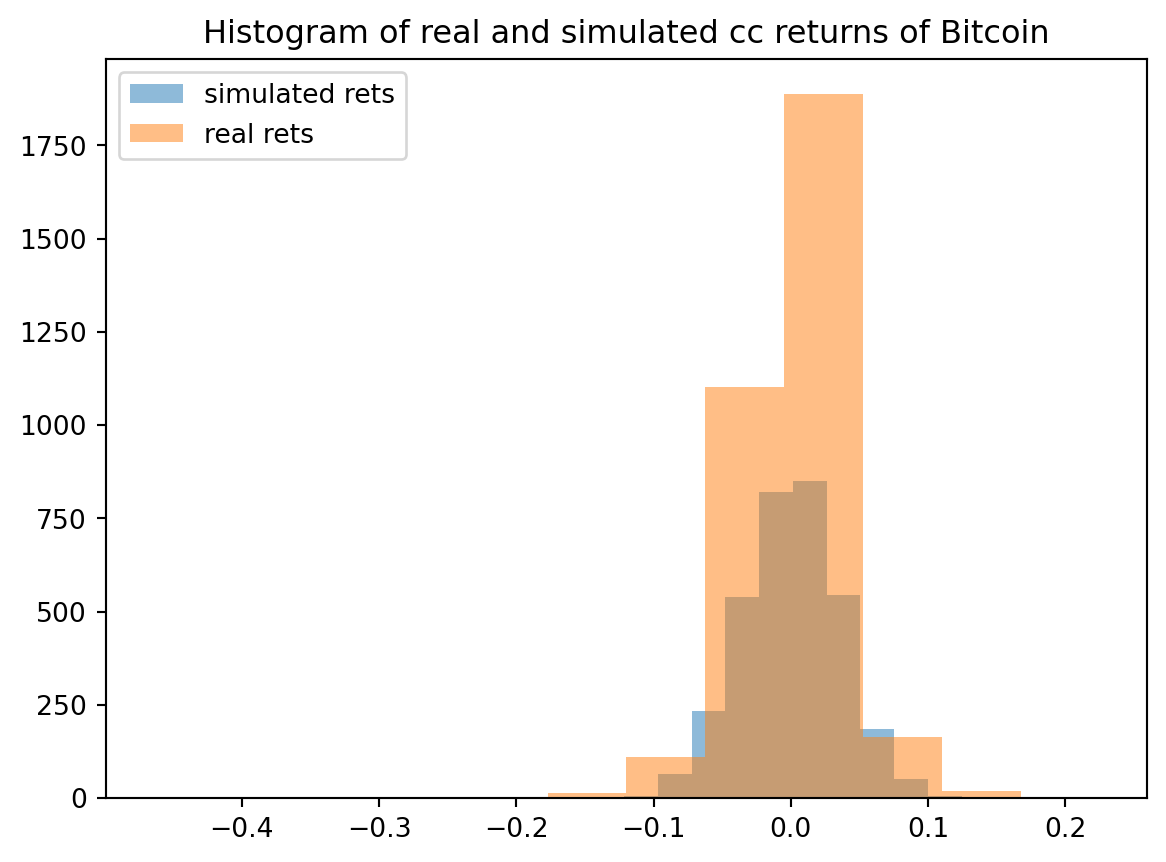
Use the mean and standard deviation of the historical cc returns of Bitcoin and simulate the same # of returns as the days we downloaded in the BTCR dataframe.
In one plot show both, the real distribution of historical cc returns and the simulated normal distribution.
Code
from matplotlib import pyplotpyplot.clf()rmean = BTCR["r"].mean()rsd = BTCR["r"].std()N = BTCR["r"].count()simr= np.random.normal(loc=rmean,scale=rsd, size=N)realr = BTCR["r"].to_numpy()bins =12pyplot.hist(simr,bins,alpha=0.5,label='simulated rets')pyplot.hist(realr,bins,alpha=0.5,label='real rets')pyplot.legend(loc='upper left')pyplot.title(label='Histogram of real and simulated cc returns of Bitcoin')pyplot.show()
Do you see a difference between the real and the simulated returns?
Al-Kadit, Ibrahim A. 1992. “Origins of Cryptology: The Arab Contributions.”Cryptologia 16 (2): 97–126.
Singh, Simon. 2000. The Code Book: The Science of Secrecy from Ancient Egypt to Quantum Cryptography. Anchor Books.